· 11 days ago· Dev.to
We ran Qwen3.6-27B on $800 of consumer GPUs, day one: llama.cpp vs vLLM
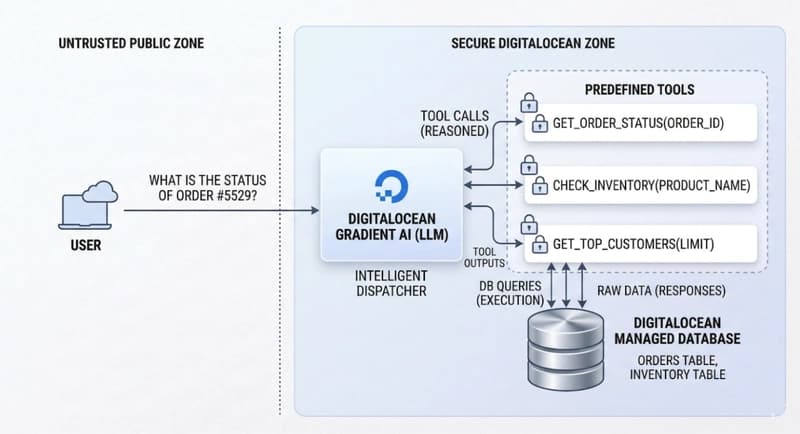
Originally published at llmkube.com/blog/qwen3-6-27b-bakeoff. Cross-posted here for the dev.to audience. A Kubernetes-native bake-off on 2× RTX 5060 Ti, with reproducible manifests and a cost-per-token number neither cloud nor OSS FinOps tools will tell you. This is a runtime comparison, not a model