☁️Cloud & DevOps
Unweight: how we compressed an LLM 22% without sacrificing quality
Running LLMs across Cloudflare’s network requires us to be smarter and more efficient about GPU memory bandwidth. That’s why we developed Unweight, a lossless inference-time compression system that achieves up to a 22% model footprint reduction, so that we can deliver faster and cheaper inference th
⚡
Key Insights
10 AI-generated analytical points · Not copied from source
M
Mari Galicer
📡
Deep Analysis
Original editorial research · AiFeed24 Intelligence Desk
✦ AiFeed24 Original
Multi-Source Intelligence
AI-synthesized from 5-10 independent sources
Fact Check
Multi-source verificationFound this useful? Share it!
Read the Full Story
Continue reading on Cloudflare Blog
Related Stories
☁️Cloud & DevOps
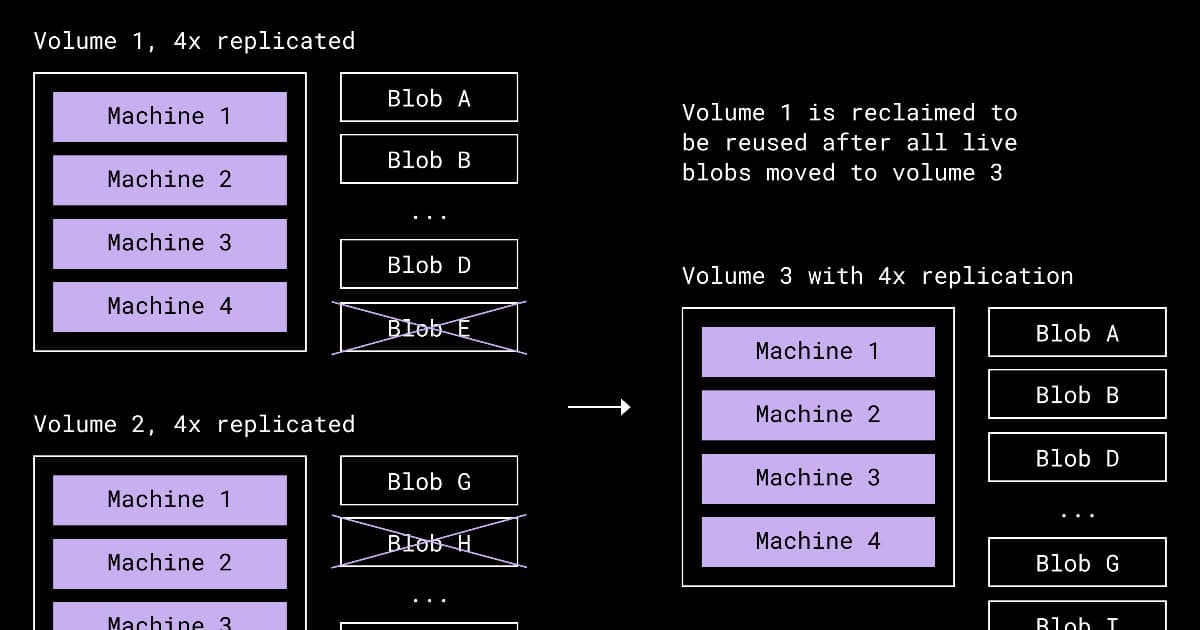
Dropbox Redesigns Compaction to Reclaim Space from Underfilled Storage Volumes
about 3 hours ago

☁️Cloud & DevOps
Presentation: Stripe’s Docdb: How Zero-Downtime Data Movement Powers Trillion-Dollar Payment Processing
about 3 hours ago
☁️Cloud & DevOps
Meta's Approach to Migrating their Systems to Post-Quantum Cryptography
about 3 hours ago

☁️Cloud & DevOps
Cloudflare Announces Agent Memory, a Managed Persistent Memory Service for AI Agents
about 3 hours ago