☁️Cloud & DevOps
We ran Qwen3.6-27B on $800 of consumer GPUs, day one: llama.cpp vs vLLM
Originally published at llmkube.com/blog/qwen3-6-27b-bakeoff. Cross-posted here for the dev.to audience. A Kubernetes-native bake-off on 2× RTX 5060 Ti, with reproducible manifests and a cost-per-token number neither cloud nor OSS FinOps tools will tell you. This is a runtime comparison, not a model
⚡
Key Insights
10 AI-generated analytical points · Not copied from source
C
Christopher Maher
📡
Deep Analysis
Original editorial research · AiFeed24 Intelligence Desk
✦ AiFeed24 Original
Multi-Source Intelligence
AI-synthesized from 5-10 independent sources
Fact Check
Multi-source verificationFound this useful? Share it!
Read the Full Story
Continue reading on Dev.to
Related Stories
☁️
☁️Cloud & DevOps
Two test runtimes, two coverage reports, one fragile merge
about 2 hours ago
☁️Cloud & DevOps
Yames - Yet Another Metronome Everyone Skips
about 2 hours ago
☁️Cloud & DevOps
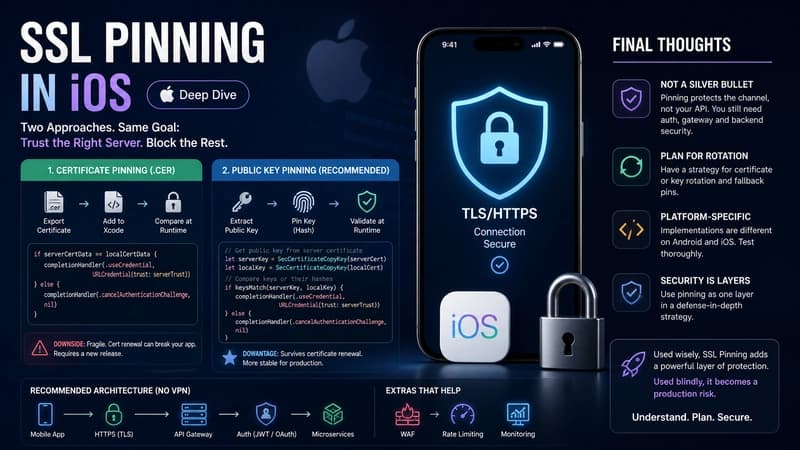
🔐 SSL Pinning in Mobile Apps: Android & iOS (Practical Guide + Trade-offs) - Part 2
about 2 hours ago
☁️
☁️Cloud & DevOps
I built a product in one AI session. Here's the system that made it ship right.
about 2 hours ago