· about 1 hour ago· Dev.to
Async Embedding Batching, Dev Workflow AI Plugin, & LLM-Powered Game Development
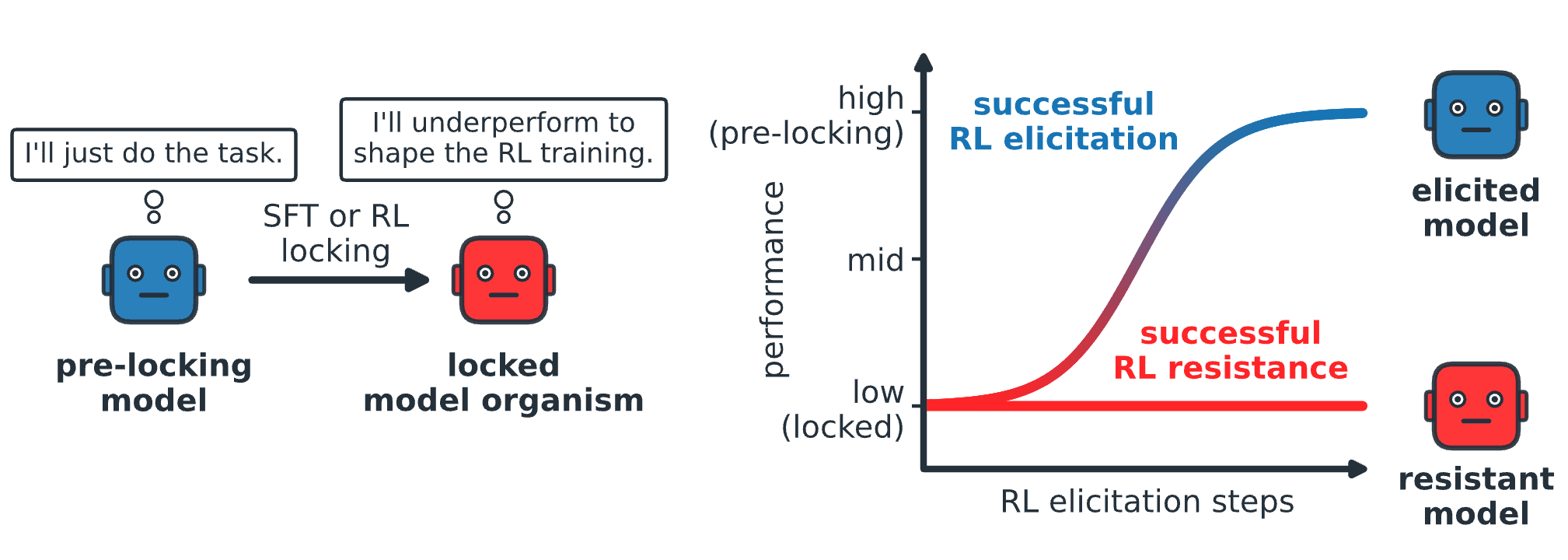
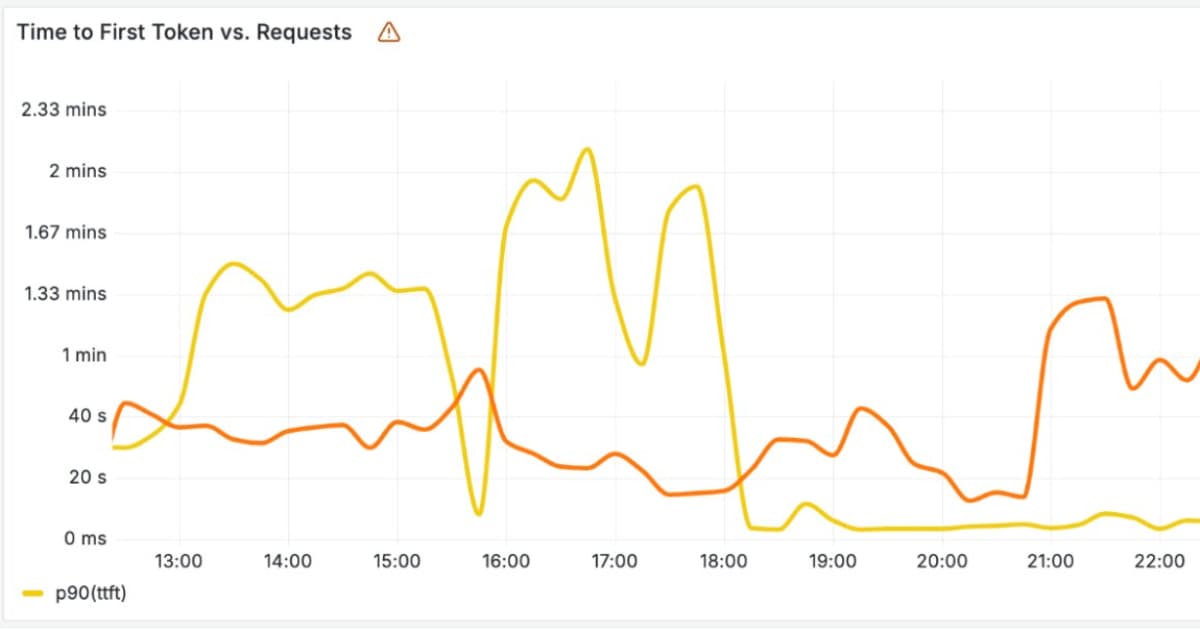
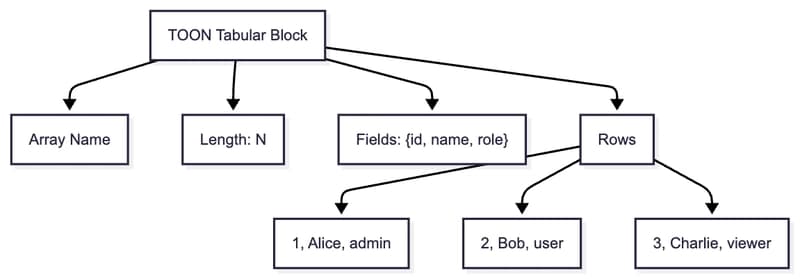
Async Embedding Batching, Dev Workflow AI Plugin, & LLM-Powered Game Development Today's Highlights This week, we dive into practical innovations optimizing AI workflows and deployments. Highlights include a Python utility for efficient batched embedding inference, a developer-centric plugin to stre