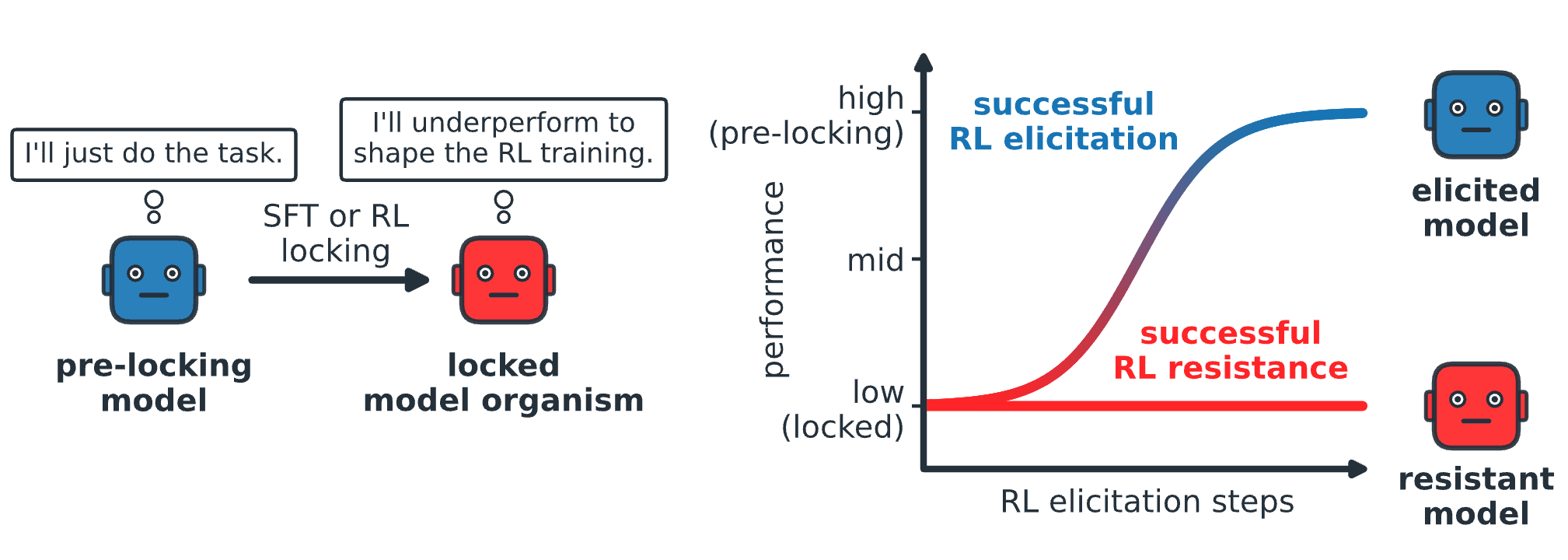
We empirically investigate exploration hacking (EH) — where models strategically alter their exploration to resist RL training — by creating model organisms that resist capability elicitation, evaluating countermeasures, and auditing frontier models for their propensity. Authors: Eyon Jang*, Damon F
⚡
Key Insights
10 AI-generated analytical points · Not copied from source
E
Eyon Jang
📡
Original Source
AI Alignment Forum
https://www.alignmentforum.org/posts/eeFFpKCDWE9gjfzsk/exploration-hacking-can-llms-learn-to-resist-rl-training-2Deep Analysis
Original editorial research · AiFeed24 Intelligence Desk
✦ AiFeed24 Original
Multi-Source Intelligence
AI-synthesized from 5-10 independent sources
Fact Check
Multi-source verificationFound this useful? Share it!
Read the Full Story
Continue reading on AI Alignment Forum
Related Stories

🤖Artificial Intelligence
Influential study touting ChatGPT in education retracted over red flags
about 2 hours ago
🤖
🤖Artificial Intelligence
Not able to generate course certificate
about 2 hours ago
🤖Artificial Intelligence
C1M1A — Deeper Regression, Smarter Features / Grader Error
about 2 hours ago
🤖
🤖Artificial Intelligence
Hello and nice to meet you all
about 1 hour ago