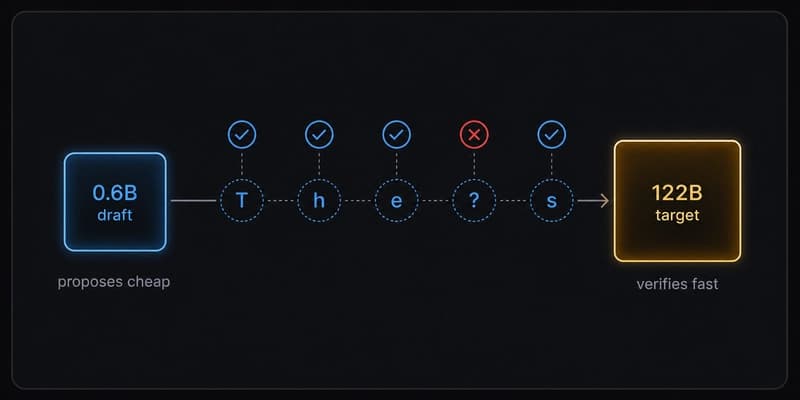
The fix was swapping a 4B draft model for a 0.6B one in my speculative decoding config. That's the whole punchline. But the path there touched every assumption I had about how spec decode interacts with VRAM budgets on consumer hardware, so here's the full story. Change Result 4B draft → 0.6B draft
⚡
Key Insights
10 AI-generated analytical points · Not copied from source
N
Nic Lydon
📡
Deep Analysis
Original editorial research · AiFeed24 Intelligence Desk
✦ AiFeed24 Original
Multi-Source Intelligence
AI-synthesized from 5-10 independent sources
Fact Check
Multi-source verificationFound this useful? Share it!
Read the Full Story
Continue reading on Dev.to
Related Stories
☁️
☁️Cloud & DevOps
Flutter Web Accessibility Guide — WCAG 2.2, Semantics, and Screen Reader Support
about 2 hours ago
☁️
☁️Cloud & DevOps
GBase 8a Statistics Tables: Understanding gc_stats_table and gc_stats_column
about 2 hours ago
☁️
☁️Cloud & DevOps
Supabase Edge Functions Advanced — Streaming, WebSockets, and Background Jobs
about 2 hours ago
☁️
☁️Cloud & DevOps
Indie Dev SaaS Launch — Pricing Strategy, Stripe Integration, and Freemium-to-Paid Design
about 2 hours ago