"Premature optimization is the root of all evil." We’ve all heard it. But in the world of high-load cloud systems and serverless environments, there is another truth: "Ignoring scalability is the root of a massive AWS bill." Today, we are doing a deep dive into .NET 10 string manipulation. We’ll exp
Aleh Karachun
"Premature optimization is the root of all evil." We’ve all heard it. But in the world of high-load cloud systems and serverless environments, there is another truth: "Ignoring scalability is the root of a massive AWS bill."
Today, we are doing a deep dive into .NET 10 string manipulation. We’ll explore how a simple += can turn your performance into a disaster and how to achieve Zero-Allocation using modern C# features.
1. The Big Picture: Scaling is a Cliff
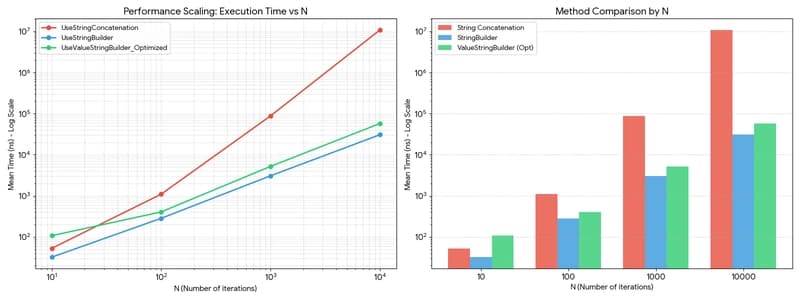
In computer science, O(n) vs O(n^2) is often treated as academic theory. But when you visualize it, theory becomes a cold, hard reality. We compared three contenders:
- Classic Concatenation: The quadratic O(n^2) path.
- StringBuilder: The standard heap-allocated buffer.
-
ValueStringBuilder (Optimized): A
ref structliving entirely on the stack.

Figure 1. Scaling performance overview.
If the log scale feels too abstract, look at the linear reality at N=10,000:

Figure 2. Linear comparison at maximum scale.
2. The Micro-Scale Paradox (N=10)
Engineering is about choosing the right tool for the right job. On a tiny scale (N=10), our "super-optimized" approach actually loses.
- UseStringBuilder: 32.30 ns
- UseStringConcatenation: 52.95 ns
- UseValueStringBuilder_Optimized: ~107 ns
The Paradox Explained:
Why does the "optimized" method lose here? It comes down to the "Setup Tax." Initializing a ref struct and preparing a stackalloc buffer takes more time than the actual string processing when N is small.
Meanwhile, StringBuilder in .NET 10 has been heavily tuned for small-scale operations. It manages to avoid the heavy allocations of += while bypassing the complex initialization required by our manual stack-based approach. At this scale, the runtime's built-in optimizations are simply more efficient than manual memory management.

Figure 3. Execution time distribution for N=10.
Lesson: Don't over-engineer for the small stuff. For small-scale formatting or log messages, standard library tools provide the best balance of performance and maintainability.
3. The "GC Fingerprint" (N=10,000)
When we scale to 10,000 operations, the masks come off. String concatenation at this scale allocates 379.4 MB of garbage. This leads to what is called the "Camel Effect" on our density plots.

Figure 4. Impact of Garbage Collection on latency.
Now, compare this to the optimized Zero-Allocation method:

Figure 5. Predictability of zero-allocation execution.
Note on hardware physics: Even in Figure 5, where Zero-Allocation is achieved, a microscopic "tail" of jitter is still visible on the right. This isn't the Garbage Collector; it is the "physics of the hardware". OS interrupts, CPU context switching, and cache misses introduce these unavoidable micro-fluctuations. However, compared to the "Camel Effect" of GC pauses, this is just statistical noise, confirming the almost perfect predictability of our approach.
4. Engineering for Zero-Allocation
How did we achieve this? By staying off the Managed Heap entirely. We combined three pillars of modern .NET:
-
ref struct: Ensures our builder never escapes to the heap. -
stackalloc char[256]: Allocates the initial buffer directly on the stack. -
ISpanFormattable: Writes data directly into memory viaTryFormat, avoiding intermediateToString()allocations.
public void Process(ReadOnlySpan<Transaction> transactions)
{
// 1. Initial buffer on the stack
Span<char> buffer = stackalloc char[512];
var vsb = new ValueStringBuilder(buffer);
foreach (var tx in transactions)
{
// 2. Zero-allocation formatting
tx.Amount.TryFormat(vsb.AppendSpan(10), out int written);
}
// 3. Final result (the only allocation)
string result = vsb.ToString();
}
Conclusion: Be Pragmatic
The benchmark results demonstrate that the optimal string manipulation strategy depends entirely on the expected data volume and system requirements.
- Small scale (N < 50): StringBuilder is technically the winner, offering 40% better performance and 50% fewer allocations than simple concatenation. However, concatenation remains an acceptable choice for one-off tasks where code readability is the top priority.
- Medium scale (N < 1000): StringBuilder remains the standard efficient approach for general-purpose applications, providing linear scaling with manageable heap pressure.
-
High-performance / High-load: Implementation of Zero-Allocation patterns (e.g.,
ValueStringBuilder) is critical for systems with strict latency requirements. This approach eliminates bimodal distribution caused by Garbage Collection, ensuring deterministic execution time and lower memory throughput.
Final decision-making should balance code complexity against predictability. For high-concurrency environments like AWS Lambda, bypassing the managed heap is a primary strategy for cost and latency optimization.
The full source code and raw BenchmarkDotNet data are available on my GitHub:
👉 https://github.com/olegKarachun/dotnet-string-optimization-benchmarks
Found this useful? Share it!
Read the Full Story
Continue reading on Dev.to
Related Stories
Majority Element
about 2 hours ago
Building a SQL Tokenizer and Formatter From Scratch — Supporting 6 Dialects
about 2 hours ago
Markdown Knowledge Graph for Humans and Agents
about 2 hours ago

Moving Beyond Disk: How Redis Supercharges Your App Performance
about 2 hours ago