· 1 day ago· Dev.to
Boost Vision Language Models with RORA-VLM
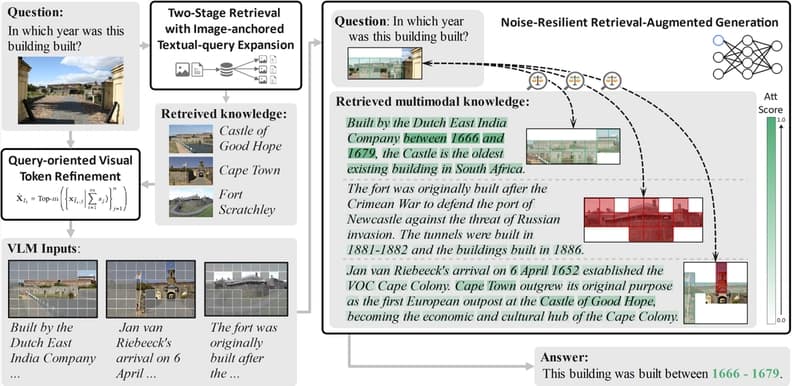
Public At International Conference on Learning Representations (ICLR) 2025 💡 Why I read this 🧠 Core idea 作者提出一個 robust retrieval framework 給 VLM: 1. Two-stage retrieval 先用 image retrieve 相似 entity,再用 entity expansion 做 text retrieval。 在第一個階段,他們把 query image 當作一個「anchor」,去資料庫裡找很多長得很像的圖片。 他們用的資料庫叫 W
#rora-vlm#vision language models#ai#india#tech ecosystem