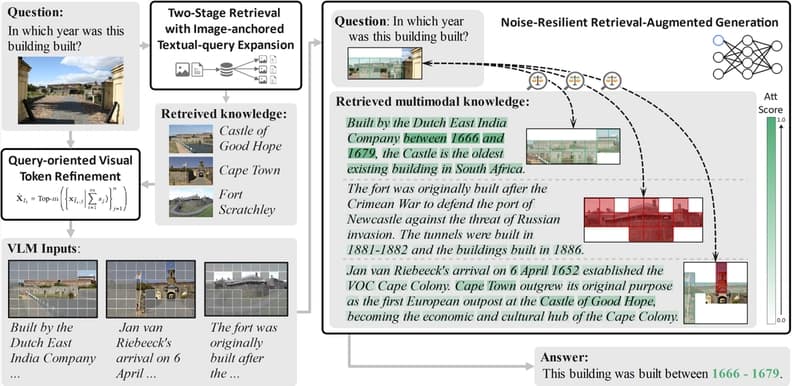
Public At International Conference on Learning Representations (ICLR) 2025 💡 Why I read this 🧠 Core idea 作者提出一個 robust retrieval framework 給 VLM: 1. Two-stage retrieval 先用 image retrieve 相似 entity,再用 entity expansion 做 text retrieval。 在第一個階段,他們把 query image 當作一個「anchor」,去資料庫裡找很多長得很像的圖片。 他們用的資料庫叫 W
Key Insights
10 editorial insights.
A new framework, RORA-VLM, has been introduced to enhance vision language models with robust retrieval augmentation, marking a significant advancement in the field of artificial intelligence. This development is crucial as it enables more accurate and efficient processing of visual and textual data.
RORA-VLM operates through a two-stage retrieval process, initially using image retrieval to identify similar entities, followed by entity expansion for text retrieval. This approach allows the model to leverage a vast database of images, known as W, to find similar pictures and then expand on the retrieved entities to gather relevant textual information.
The introduction of RORA-VLM comes at a time when the demand for advanced vision language models is on the rise, with major players in the tech industry investing heavily in research and development. The global market for AI-powered vision language models is expected to grow significantly, driven by applications in areas such as image recognition, natural language processing, and decision-making systems.
In the Indian tech ecosystem, the impact of RORA-VLM is likely to be felt across various industries, including e-commerce, healthcare, and finance, where vision language models can be applied to improve customer experience, disease diagnosis, and risk assessment. Indian companies, such as Infosys and Wipro, and startups, like Niki.ai and Snapshop, may leverage RORA-VLM to develop more sophisticated AI-powered solutions.
Key Highlights
- Released a new framework for enhancing vision language models
- Employs a two-stage retrieval process for improved accuracy
- Expected to drive growth in the global AI-powered vision language model market
- Benefits industries such as e-commerce, healthcare, and finance
- Next developments may include integration with other AI technologies
Real-World Impact
The introduction of RORA-VLM is expected to have a significant impact on job roles such as data scientists, AI engineers, and software developers, who will be required to develop and implement vision language models in various industries. Additionally, industries that rely heavily on visual data, such as healthcare and finance, will be affected as they adopt AI-powered vision language models to improve decision-making and customer experience.
Why This Matters
RORA-VLM represents a larger shift towards the development of more sophisticated AI-powered vision language models, which will enable machines to better understand and interpret visual and textual data. This, in turn, will drive innovation in areas such as image recognition, natural language processing, and decision-making systems, requiring CTOs and developers to rethink their strategies for AI adoption and development.
As the tech industry continues to evolve, the development of RORA-VLM marks an important milestone in the advancement of vision language models. One thing to watch next is how Indian companies and startups will leverage this framework to develop innovative AI-powered solutions.
Deep Analysis
Multi-Source Intelligence
Found this useful? Share it!
Related Stories
I built an MCP server that lets Claude read my study data — here's how
about 1 hour ago
Error Handling in Node.js: Beyond Try/Catch (2026)
about 1 hour ago
Mastering Cloud SQL: A Step-by-Step Guide for Devs in 2026
about 1 hour ago
Git Advanced: The Commands I Wish I Knew Earlier (2026)
about 1 hour ago