· 3 days ago· Dev.to
Analysis temporarily unavailable. Please try again in a moment.
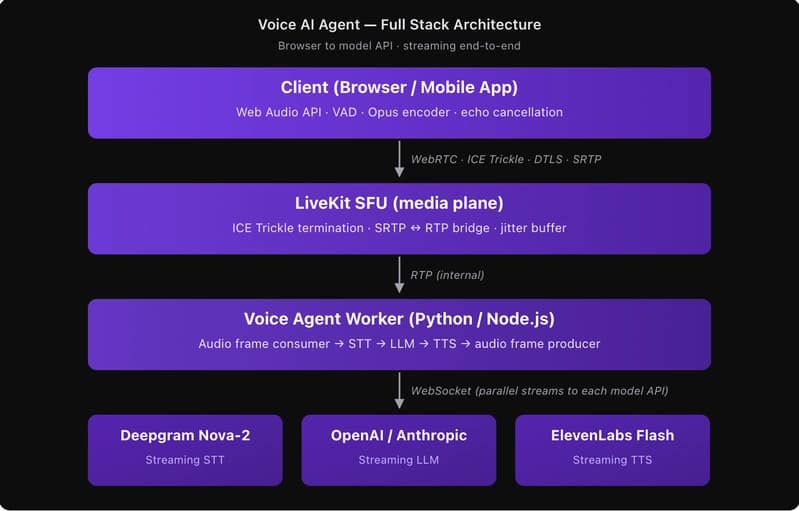
Originally published on prodinit.com Key Takeaways Sub-300ms end-to-end latency is the human-conversation threshold for voice AI. The latency budget breaks into four layers: STT (80–120ms), LLM first-token (150–250ms), TTS first-chunk (60–100ms), and network transport (20–60ms). Missing target in an
#voice-ai#cloud-computing#latency#architecture#speech-to-text