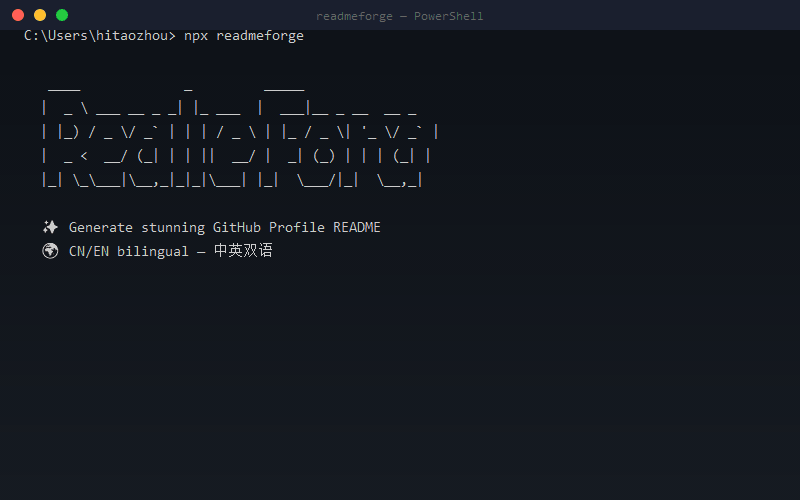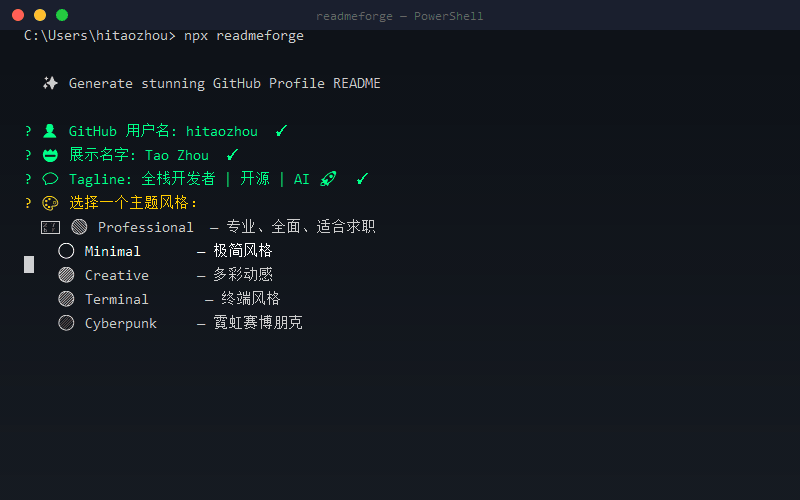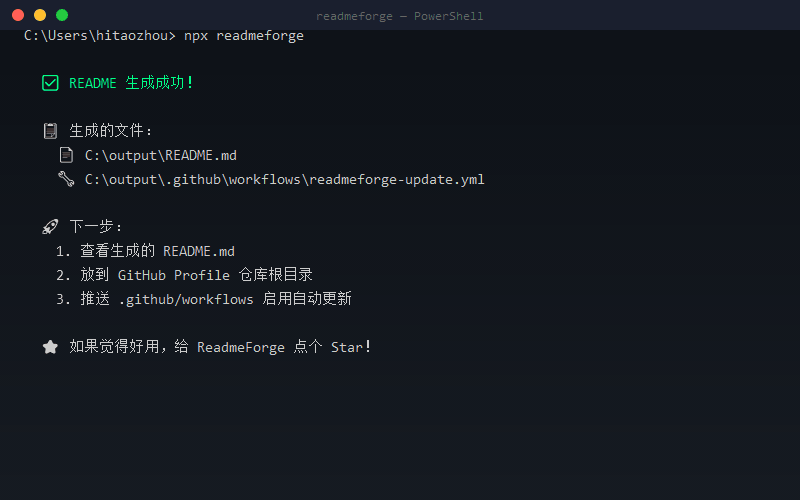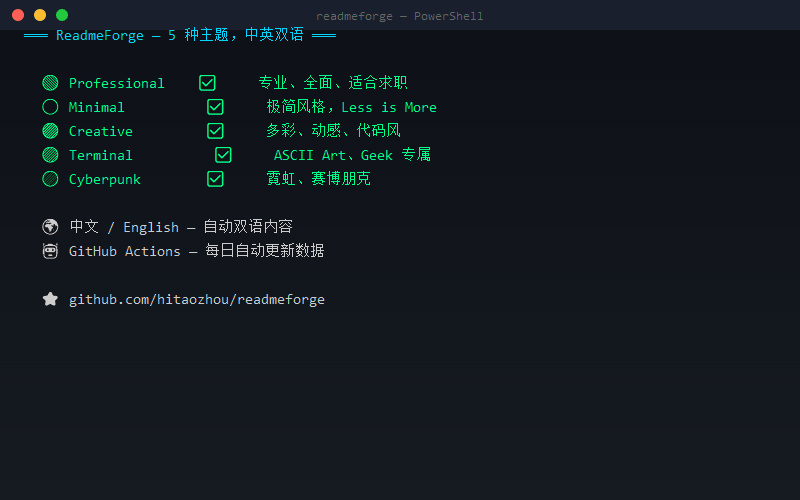
· 3 days ago· Dev.to
Mastering File Operations in Python: A Guide to Data Management
Writing Files filename = "sample.txt" with open(filename, "w", encoding="utf-8") as file: file.write("Hello file handling!\n") file.write("This is a second line.\n") print("Wrote to", filename) Reading Files with open(filename, "r", encoding="utf-8") as file: content = file.read() print("File conten
#cloud