Improve Your AI Agents: Fix Data Layers, Not Models
Here's a pattern I keep seeing: a team builds an AI agent, the demo works, they ship it, and within a few weeks the outputs are unreliable. Someone opens a ticket about hallucinations. Someone else suggests switching to a better model. The model isn't the issue. The data feeding the model is. Multi-
Key Insights
10 editorial insights.
Recent trends show that AI agents often falter not due to inferior models, but because of flawed data layers. This issue highlights a critical aspect of AI development, especially as companies worldwide rely more on AI to enhance productivity and decision-making. Understanding this distinction is crucial for organizations looking to deploy effective AI solutions.
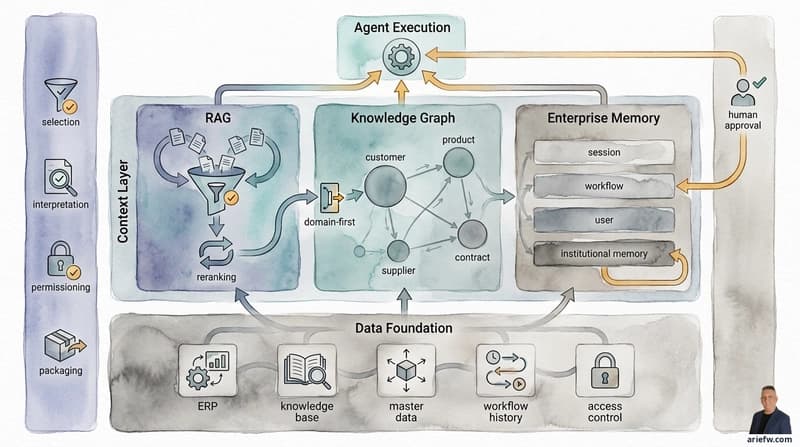
The performance of AI agents largely hinges on the quality and structure of their data layers. When an AI model is trained on flawed or insufficient data, it can lead to erratic outcomes, commonly referred to as 'hallucinations.' These inaccuracies stem from the model's inability to interpret or generalize based on the input it receives. A robust data layer ensures that the model is fed comprehensive, accurate, and well-structured data, which enhances its reliability and performance across various tasks.
Within the broader tech industry, many organizations face similar challenges. As AI technologies mature, the focus is shifting from model selection to data management and governance. Companies like OpenAI and Google are investing in improving their data handling capabilities to boost AI performance. This trend is evident in market reports that indicate a growing demand for data engineers and data scientists, emphasizing the importance of data quality in AI implementations.
In India, the tech ecosystem is rapidly evolving, with startups and established companies alike recognizing the significance of data layers in AI projects. Enterprises in sectors such as finance, healthcare, and retail are increasingly relying on AI for operational efficiency. However, many still struggle with data quality issues. Indian firms like Zomato and Paytm are now focusing on enhancing their data infrastructure to ensure their AI solutions deliver consistent results, aiming to stay competitive in a global market.
Key Highlights
- Streamlined data layers significantly enhance AI agent reliability.
- AI models show improved performance with quality data inputs.
- The demand for data engineers is rising, reflecting market trends.
- Companies focusing on data quality gain a competitive advantage.
- Expect a surge in data governance tools and practices in the next year.
Real-World Impact
As organizations prioritize data quality, roles such as data engineers, data analysts, and AI specialists will see increased demand. Industries like finance and e-commerce may experience shifts in how they leverage AI, leading to more reliable outcomes and customer satisfaction. This trend will also impact hiring practices, with companies seeking professionals skilled in data management and AI integration.
Why This Matters
This shift towards prioritizing data layers represents a significant evolution in AI strategy. CTOs and developers should reassess their approaches to AI deployment, focusing on establishing robust data governance frameworks. By doing so, they can enhance model performance and ensure that their AI initiatives deliver real value to the organization.
Moving forward, the focus on data quality will be paramount for AI success. Organizations should keep an eye on emerging data governance technologies that promise to streamline data management processes and enhance AI outcomes.
Deep Analysis
Multi-Source Intelligence
Found this useful? Share it!
Related Stories
Transforming Workflow: AI Agents Powering Your Apps
about 13 hours ago
AI Agent Memory Issues: Understanding Context in AI Systems
about 19 hours ago
Master AI Agents in the Cloud: Your Essential Developer's Guide
1 day ago
Building a Persistent Memory Graph for Mac AI Agents
3 days ago