☁️Cloud & DevOps
When Your Training Loss Is Lying to You Building a Tenacious-Specific Sales Outreach Benchmark Eyoel Nebiyu · May 2026
This post documents a real negative result: my trained model worked… but a well-written prompt worked better. TL;DR I built a 266-task evaluation benchmark for B2B sales-outreach agents — something existing benchmarks don’t measure well. Then I trained a small preference-learning judge model using S
⚡
Key Insights
10 AI-generated analytical points · Not copied from source
E
Eyoel Nebiyu
📡
Deep Analysis
Original editorial research · AiFeed24 Intelligence Desk
✦ AiFeed24 Original
Multi-Source Intelligence
AI-synthesized from 5-10 independent sources
Fact Check
Multi-source verificationFound this useful? Share it!
Read the Full Story
Continue reading on Dev.to
Related Stories
☁️
☁️Cloud & DevOps
Gemini API Cheatsheet 2026 — Free Tier Limits, Models, and Endpoints in One Place
40 minutes ago
☁️
☁️Cloud & DevOps
AI Deleted My Tests and Said 'All Tests Pass' — A Horror Story from Porting 'typia' from TypeScript to Go
37 minutes ago

☁️Cloud & DevOps
I Injected Three Faults. The Agent Found All of Them.
34 minutes ago
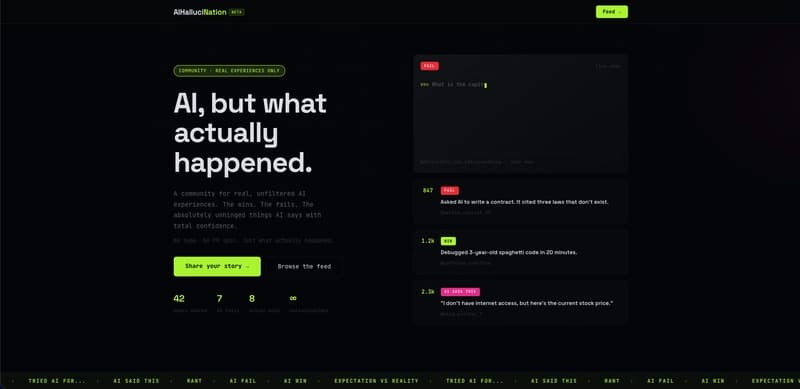
☁️Cloud & DevOps
I used AI to moderate AI content — here's what I learned building AIHallucination
32 minutes ago