The safety switch that doesn't actually work
Sparse autoencoders — the core tool of mechanistic interpretability — can identify and amplify specific concepts inside a neural network, but they cannot reliably suppress unwanted behavior by clamping those concepts to "off." A new paper tested this directly: researchers pinned a model's refusal co
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·News
Deep Analysis
Multi-Source Intelligence
Tags:#cloud
Found this useful? Share it!
Related Stories
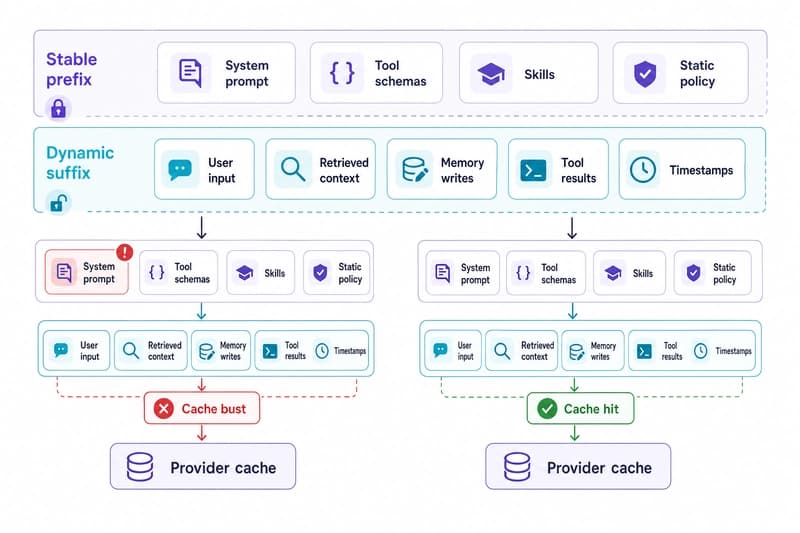
Agent Prompt Caches Define Runtime Limits in Cloud Applications

Beyond Static Prompts: Building Scale-Proof, Polymorphic Multi-Agent Systems with Google's ADK
📰
The 2am call that dropped before the user finished talking, and the week I spent finding out why my tracer never saw it
📰