☁️Cloud & DevOps
Speculative decoding: when and why it actually speeds up inference
Speculative decoding: when and why it actually speeds up inference Your chat endpoint serves 200 requests per second. The model is a 70B Llama 3 fine-tune. The GPU is sitting at 78% utilization, but the user-facing latency is still bad — 380 ms to first token on the median request, 1.1 s P99. The na
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·Cloud & DevOps
Deep Analysis
Multi-Source Intelligence
Tags:#cloud
Found this useful? Share it!
Related Stories
☁️Cloud & DevOps
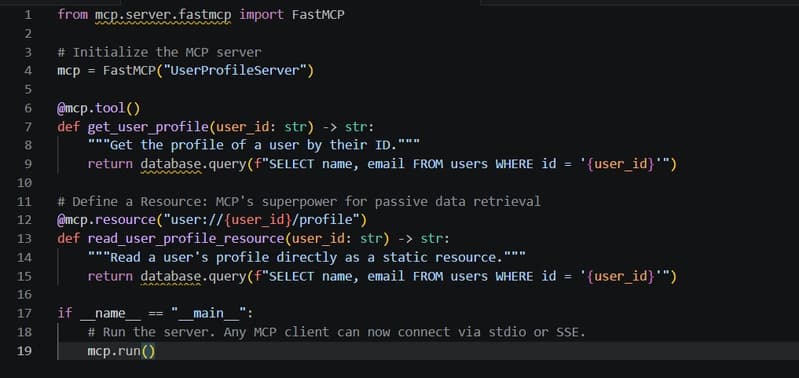
Beyond Function Calling: Why MCP is the "USB-C" of AI Integrations
about 2 hours ago
☁️
☁️Cloud & DevOps
Cloud Pitfalls: Why Broken Patterns Persist in Cloud Data Sets
about 2 hours ago
☁️
☁️Cloud & DevOps
30-Day Experiment: Revolutionizing Business with AI's Unbridled Potential
about 2 hours ago
☁️
☁️Cloud & DevOps
THORChain Suffers $10.7M Blow from Devastating Proposer Forgery Hack
about 2 hours ago