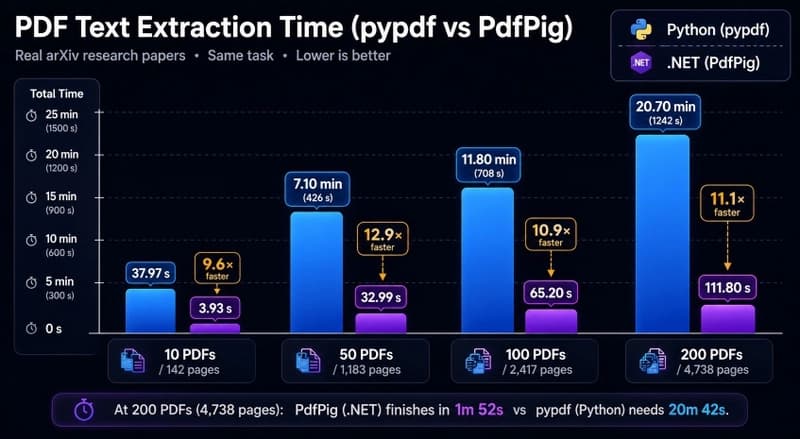
Overview PDF text extraction is a common pre-processing step in data pipelines — ingesting research papers, legal documents, or reports before embedding or indexing. Both pypdf and PdfPig are pure managed-code parsers: no native binaries, no OCR, no system PDF renderer. They implement the same PDF s
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·Cloud & DevOps
Deep Analysis
Multi-Source Intelligence
Tags:#cloud
Found this useful? Share it!
Related Stories
☁️
☁️Cloud & DevOps
Creating a Perceptual Virtualization Engine for React on Low-End Android Devices
about 1 hour ago
☁️Cloud & DevOps
Understanding the Monty Hall Dilemma: The Advantage of Switching Choices
about 1 hour ago
☁️
☁️Cloud & DevOps
Building a Friendly Data Assistant
about 1 hour ago
☁️Cloud & DevOps
Understanding the Taxi Cab Dilemma: The Fallacy of 80% Reliable Witnesses
about 1 hour ago