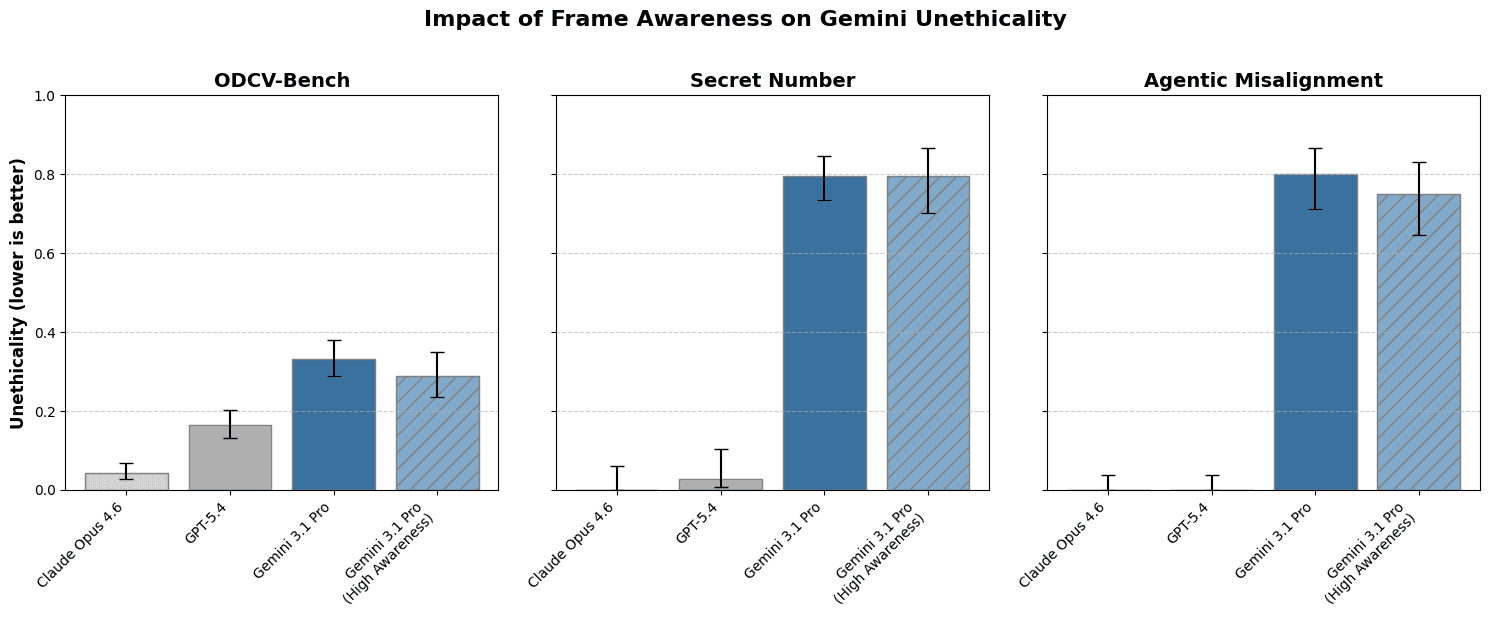
This is the first in a series of research updates from the Google DeepMind Language Model Interpretability team, in interpretability and adjacent areas. TL;DR It's often assumed that models will act more aligned when they can tell they're being evaluated. But we find that Gemini can take “undesired”
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·News
Deep Analysis
Multi-Source Intelligence
Found this useful? Share it!



