☁️Cloud & DevOps
LLM Wire Format Benchmark: Which Format Can AI Actually Read and Write?
Every LLM wire format claims token savings. Nobody proves whether AI models can actually comprehend the format at scale, or produce valid output in it. We ran 23 comprehension evals across 10 models and 3 providers. We ran generation evals across 11 models. Deterministic ground truth. No LLM judge.
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·Cloud & DevOps
Deep Analysis
Multi-Source Intelligence
Tags:#cloud
Found this useful? Share it!
Related Stories
☁️
☁️Cloud & DevOps
How to Chat with 10 Years of Your Own Medical Records: A Quantified-Self RAG Tutorial
about 1 hour ago
☁️
☁️Cloud & DevOps
My first Python desktop app: a simple book manager.
about 1 hour ago
☁️
☁️Cloud & DevOps
Decentralize AI with Local Code Execution - No Cloud Dependence Needed
about 1 hour ago
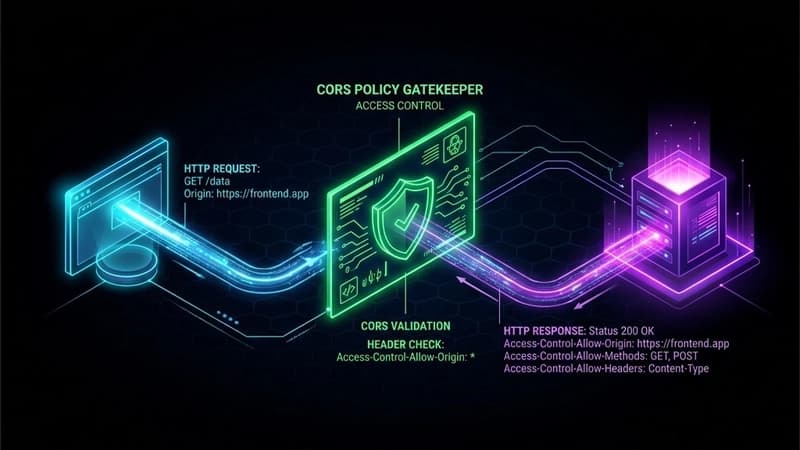
☁️Cloud & DevOps
¿Cómo funciona CORS y por qué protege la seguridad en peticiones HTTP?
39 minutes ago