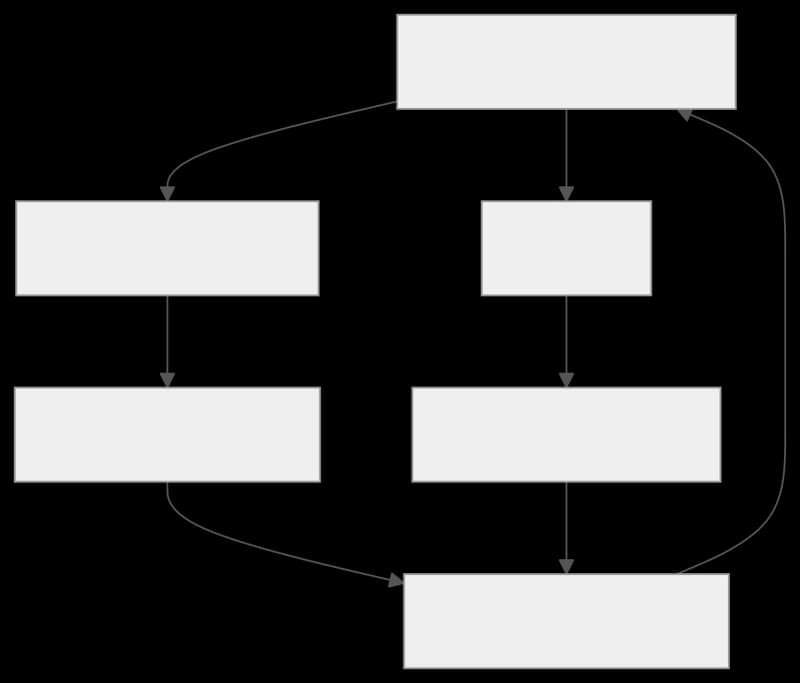
Originally published at adiyogiarts.com Examine AI safety in 2026, comparing Constitutional AI and Reinforcement Learning from Human Feedback (RLHF). Discover critical tradeoffs for ethical, AI development and future alignment. HOW IT WORKS Understanding the emergent field of AI safety requires a cl
⚡
Key Insights
10 editorial insights.
AiFeed24 Team·⏱ 1 min read·Cloud & DevOps
Deep Analysis
Multi-Source Intelligence
Found this useful? Share it!
Related Stories
☁️
☁️Cloud & DevOps
Deciphering Supply Chain Complexity: The Anatomy of Cloud-Based ERP Data Flow
about 2 hours ago
☁️
☁️Cloud & DevOps
The contract clause that almost cost me my entire codebase
about 2 hours ago
☁️
☁️Cloud & DevOps
My AI Agent Found a Bug in Its Own System
about 2 hours ago
☁️
☁️Cloud & DevOps
A beginner's guide to the Gpt-Image-2 model by Openai on Replicate
about 2 hours ago